
Chapter 2: Taxonomy and Phylogeny

While it is uncommon, people sometimes give names to individual plants. For example, in Sequoia National park stands ‘General Sherman’, considered to be the largest organism living on earth. Because organisms are discrete packages (i.e., with boundaries in space and time) it certainly possible to name them. But there are an awful lot of them and it is simply impractical to name them all. However, if one observes organisms, it is quickly apparent that they occur in groups, i.e. there are groups of them that look similar and thus the group can be considered an entity itself. Moreover, additional study will usually reveal that identified (i.e., defined) groups of organisms can often be: (1) subdivided into smaller groups and (2) lumped together into bigger groups; that is, that the diversity of organisms is organized into clusters of similarity and there are clusters of the clusters. These biological patterns seek an explanation: why do organisms come in groups and why are there groups of groups?
Even if organisms did not ‘naturally’ occur in groups it would be important for biologist to define groups; there is simply so much biological diversity that some sort of ‘filing system’ is required to organize it all. Thus, there are two aspects to organizing organisms into groups: (1) a practical aspect, producing a way to manage all the variety of organismal life, to arrange its vast diversity, (2) a mechanistic (process) aspect, producing a system that will allow biologists to understand mechanisms that result in the patterns of diversity, e.g., why there are groups. To a large extent these two aspects can be satisfied simultaneously, i.e., there are systems that categorize life easily and also allow users to study the processes (evolutionary mechanisms) that lead to the categories. However, the biological landscape is vast; clusters range from groups (species, or perhaps subspecies) that might have less than 1000 organisms that all ‘look’ very similar to groups (families, orders) that are comprised of millions of individuals, with members that do not ‘look’ very similar yet do possess some ‘fundamental similarities.’ With such a span in scale one should appreciate that there may be situations where a system that is useful to consider the evolutionary relationships (i.e., the phylogeny) between groups of organisms may not very handy as a filing system. Or, looking at it from a different perspective, classification schemes that easily organize life’s diversity may not do so in a way that reflects the phylogeny of different groups. An example familiar to most biology students would be ‘reptiles’, a handy group in terms of classification (reptiles are vertebrates that aren’t amphibians, birds or mammals), but a group that does not represent phylogeny. This book is primarily about organisms. And while in general it will use a phylogenetically based classification scheme, occasionally it will consider groups that are ‘artificial’ and do not reflect a phylogenetic entity, examples would be ‘green algae’ and ‘gymnosperms’.
We will be dealing with scientific names, and the groups that they describe, throughout the book and it is important to appreciate the basis and the limitations of the naming. Shakespeare asks “what’s in a name?” and answers with the implication that names are basically trivial. But names are profoundly significant in ways that often are not appreciated. Like water to a fish and air to humans, we are so immersed in names that we rarely stop to consider them. But names say much about humans, about how we think and what we think. Indeed, it is probably the case that names not only reflect how we think, they may actually dictate how we think. Names reflect the organization by which we view things and the way we process the information that we receive. While classification is useful whenever one is faced with a large number of variable entities, we need to consider to what extent our classification is a reflection of our thought (i.e., we are imposing order on something that isn’t really ordered) , or a reflection of reality (i.e., there is an order that we are describing), or something in between. Stated another way, names reflect an organization and it is important to consider whether the organization is inherent to what is being named or inherent to our minds.
Keep in mind that naming is a grouping process, i.e., it is a mechanism to put ‘things’ (in our case biological things) together. Faced with diversity, humans lump things together into categories, putting similar things together into groups; this makes the diversity more manageable and this is what classification (naming) is all about. At the same time, one should appreciate that any classification, in fact, the very process of ‘naming’, results in a loss of information to the extent that any organism varies from the norm that characterizes the group. The name ‘tree’ sets up a classification of living things, one that is both useful and arbitrary; not all trees are the same and describing something as a tree strips an organism its individuality. The same could be said for the terms ‘sequoia’, ‘Sequoiadendron’, and ‘Sequoiadendron giganteum’. For any named biological group, it is important to consider how ‘real’ the group is: do the entities naturally fall together or are we just putting them together as a means to simplify the system. If the groups are ‘real’ (valid) a biologist might consider what processes might relate to their validity; what process forms the group?
Thus the fundamental question to address when naming groups of things is what criteria will be used to group them. For instance, if you are classifying motor vehicles one might group them based on color, on manufacturer, or on type of vehicle. When considering organisms, deciding what criteria to group them on is a tough question: organisms are exceedingly diverse and they differ in myriad ways. Because living things have many, many characteristics, there are many different ways that they can be grouped. Moreover, until some goal has been attached to the classification, there is not ‘right’ way for it to be done; it is simply an arbitrary way to simplify a diverse system. Classifying cars based on color is certainly easy and, in some cases, might be useful, but it is not very useful if one’s goal is to explain the overall patterns in car variation.
Two features make a classification easier to develop and make the entities thereby defined more ‘real’, i.e., an accurate representation of the reality. One feature relates to the pattern of variation. Consider a group of organisms that has only one characteristic, or perhaps only one characteristic that might distinguish one organism from another, for example, a group of organisms that are all the same except for length. Figure 2 (a) and (b) show two such groups of organisms, one where a classification (naming) is an accurate reflection of reality and one where it is not. Both plots are ‘frequency histograms’, showing the distribution of individuals of different sizes. The difference between the two is in the pattern of variation. The group of organisms in 2(a) is easy to classify into three groups because the there are ‘gaps’ in the distribution. A statistical way of describing what is shown in 2(a) is that one can define groups (‘small’, ‘medium’, ‘large’) so that the variation within a group is small compared to the variation between groups. The group of organisms in figure 2(b) is less easily classified because there are no gaps in the distribution of organisms of different sizes; there are no obvious groups, and whatever group you might define has as much variation within it as there is between that group and the remainder of organisms. Note that it certainly is possible to classify the organisms shown in 2(b); we could divide them into that are ‘small’ (less than 6 units in length), ‘medium’ (greater than 6 but less than 16 units in length) and ‘large’ (16 units or more in length). Although such a classification is arbitrary and not an accurate reflection of reality, this does not mean that it might not be useful.
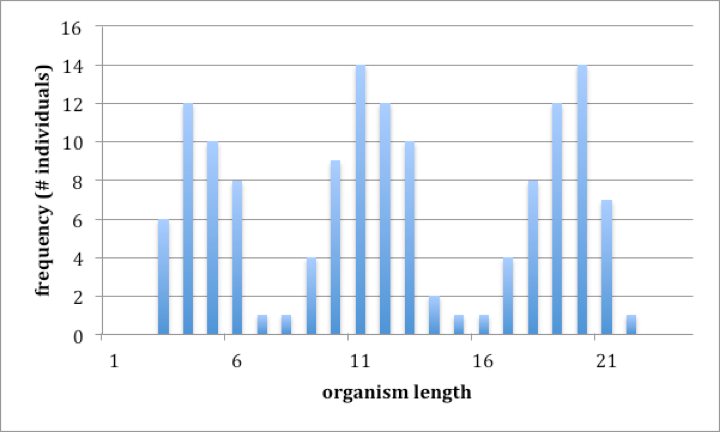
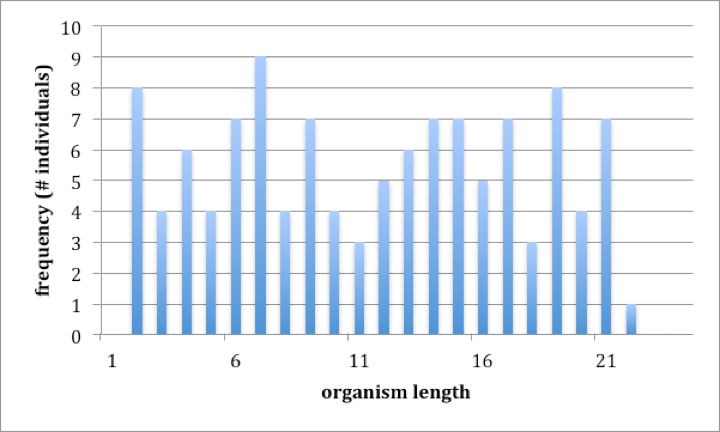
Fig. 2a (left) and 2b (right) Two examples of variation within a group of organisms. Both plots are frequency histograms, showing the number of individuals within a series of size classes.
A second factor that makes classification more ‘real’ is a correlation between different characteristics. If all the small organisms of figure 2(a) were round, the medium sized one’s square, and the large ones cylindric, there would be a correlation between size and shape. This would make the categories (small, medium and large) more justifiable; it would make them more ‘real’. Alternatively, if all the size groupings had all three shapes it would make the categories based on size (or based on shape) less real.
In general, organisms show variation that is discontinuous and they exhibit correlation in variation of different characters, and both these features make classification easier. These pattens of nature not only make classification of organisms simpler, by reducing the number of characters that one needs to consider, it also hints that there are better, or perhaps even a ‘best’, way to classify living things. This might be described as a ‘natural’ classification’, one that is based on ’fundamental similarities’. This idea was apparent to early naturalists. Carl Linnaeus, who developed one of the first classification schemes, recognized that his technique of classification, although useful, was flawed because it was not ‘natural’, i.e., it put things together based on features that did not correspond to many other features. His categories were useful because they put organisms into bins and made their diversity much more manageable, but Linn ae us appreciated that there was an organization to the diversity of living things and that this organization was not always reflected in his categories.
If there was an organization to the diversity of living things, there should be a reason for this. Three hundred years after Linnaeus, Charles Darwin, who was an excellent student of classification (of organisms as varied as beetles, orchids and barnacles) , came up with an explanation for the correlated variation and for the observation that living things appeared to fall into ‘natural’ groupings: it was consequence of the process of evolution, the changes in the characteristics of groups of organisms through time. The fundamental similarity of groups of organisms was due to the fact that together they shared a common evolutionary ancestry. Indeed, Darwin’s taxonomic acumen was highly significant to his elucidation of the process of evolution. He made two key observations that were connected to his understanding of taxonomy:
- in widely separated parts of the world where conditions are similar, for example, deserts in South America and in Africa, organisms often look similar even though they are not ‘fundamentally similar’;
- in one region of the world where conditions varied considerably within a relatively small geographic area, e.g., going from plains to mountains in southern South America, organisms that on first examination seem very different, upon closer study are ‘fundamentally similar’.
The process of organic evolution explained both of these patterns; in the first instance, convergent evolution could cause organisms that are fundamentally different (i.e., not closely related) to look superficially similar; in the second case divergent evolution (adaptive radiation) could cause fundamentally similar (i.e., closely related) organisms to diversify and look different. It can be seen that although evolution explains different reasons why things might look alike, it does NOT, at least initially, explain how one might group things: should it be on the basis of ‘basic, i.e. fundamental, similarity’ and thus combine things that may not look that similar until ‘closely examined’ (see figure 3 which shows two different members of the cactus family, a leafy cactus and a more ‘normal’ looking cactus); or should things be grouped on the basis of ‘superficial similarity’, i.e. group things if, on the surface, they look similar (see figure 4 which shows two plants that look superficially similar yet are ‘fundamentally’ different).
The distinction may seem petty (i.e. what is the difference between superficial similarity and fundamental similarity), but it has real consequences because perceptions vary. For example, people commonly group flowers on the basis of flower color, which is one of the most easily perceived characteristics of plants, but it turns out to also be one of the most superficial.


Fig. 3 These two plants are closely related and both in the cactus family, yet they ‘look’ very different, with the Pereksia (on the left) having a more typical plant form with typical leaves and branches, while the saguaro cactus on the right has evolved a very different form with no obvious leaves, an unusual branching pattern and an abundance of spines.


Fig. 4 Convergent evolution in plant form. The plant on the left is a euphorb that is not at all closely related to the cactus on the right. Although similar in form (unbranched, lacking typical leaves, having spines), this is not the result of a close evolutionary ancestry, but is the result of convergent evolution, two groups of plants ‘converging’ on a form that presumably is useful under arid conditions.
For one particular group of people, biologists, Darwin’s theory of evolution did provide a rationale for grouping and naming living things, organisms should be classified based on their phylogeny, their evolutionary ancestry, i.e., their fundamental similarities. For those who are studying organic diversity it would desirable to group things based on ‘fundamental similarities’ (= evolutionary ancestry) because, among other things, it allows us to view the consequences of evolution. But we are still left with the question of how to recognize phylogenetic groups. From pre-Linnaean times through Darwin and up until the middle of the last century, sci entists searched for features that they thought reflected ‘fundamental similarities’. After Darwin’s ideas were accepted, scientists realized that what they were looking for were features that reflected the evolutionary past of organisms. But these characteristics are elusive entities and no one really knew if they had found one because most evolutionary history is impossible to trace—the fossil record is grossly inadequate except for large-scale overviews.
Over the last fifty years molecular biology brought new approaches to taxonomy. It allows organisms to be compared on the basis of similarities in the sequences of amino acids in proteins or sequences of nucleotide bases in nucleic acids (DNA, RNA). These are more than just new features to be compared; they are features that one can argue do reflect evolutionary lineage. Through time, changes accumulate so that the longer the time since two lines diverge the more differences that accumulate in the sequence of amino acids in proteins or nucleotide bases in nucleic acids. One might argue that this is how classification has always been done, that the assumption has always been that groups ‘accumulate’ more and more differences through evolutionary time, forming separate groups with divergent characteristics. Although this is true in a very general sense, classification has always involved ‘character weighting’, i.e., observers have always felt that some characteristics, ones that are less easily modified by natural selection should have more ‘weight’ in a classification than others, characteristics, e.g., flower color, that are readily shaped by evolution and thus might occur independently in two lines that are not phylogenetically related. The formation of groups is based not just on the accumulation of differences but rather the acquisition of key differences, the differences that reflect phylogeny. Molecular biology not only provides a tremendous increase in characteristics that can be compared. It additionally provides characteristics that are unlikely to be selected for by natural selection. This is significant because if two organisms share a feature this can be explained two ways: (1) it may reflect a common ancestry (‘fundamental’ similarity) , or (2) it may reflect a common selective force (‘superficial’ similarity). However, if two organisms share a feature that is unlikely to be selected for then the only explanation involves a common ancestry. Assuming that one wants a classification based on ancestry, then using molecular data provides multiple ways to trace ancestry.
One feature of biological classification from the time of Linnaeus to now, and a feature of most (but not all) classifications, is that they are hierarchical, with species grouped into genera, genera into families, families into orders, orders into classes, classes into phyla and phyla into kingdoms (and, some would add, kingdoms into domains). However, with the exception of species (whose definition we will consider later in the course), none of these levels is defined—a genus is a group of related species, but how closely related is never specified. Thus, although it is often the case that there is agreement that a group of living things represents a taxonomic entity, exactly what level that group should be placed at, and how this group relates to other groups, may be quite controversial. Moreover, the seemingly logical idea that groups should be organized on the basis of evolutionary ancestry doesn’t mesh very well with a classification that has levels—evolution doesn’t necessarily operate in a way to produce levels; and there is no reason to assume that the levels produced on one branch might coincide with levels on another branch. One can certainly devise classification schemes that more closely match the way that we believe evolution operates; but these schemes will not be as useful in pigeon-holing (categorizing) living things. As is the case with many concepts (and in fact with words themselves!) one must balance between utility and accuracy; useful concepts often distort reality but making them more real often renders them less useful.
Most biologists approach classification from a ‘cladistic’ viewpoint that is centered on the idea that evolution produces ‘clades’ (groups) as a result of the splitting of a previously existing clade. Seen through time one would see a branching diagram. In general, this probably reflects the pattern of evolution and the development of diversity. But we have good evidence that groups not only split but sometimes merge (e.g., the endosymbiont theory for the appearance of eukaryotes; secondary endosymbiosis and the origin of multiple algal groups) and neither cladistic approaches or a hierarchical system deals well with this possibility.
For most of this book we will speak of groups that are generally considered ‘real’, that is, a group of organisms that are set off, in terms of phylogeny and in terms of characteristics, from other living things. A non-phylogenetic classification of the groups covered in this book is here (Table 1). Because our focus is on organisms and their diversity, we will be less concerned with the exact placement of the group in a taxonomic scheme or the exact phylogenetic relationship between one group and others. Some of this information is covered in the phylogeny sections of the ‘fact sheets’ for specific groups found in the Organisms section of the book. But note that the text as a whole is NOT organized along phylogeny/taxonomy lines. In fact, I will refer to a number of ‘artificial’ (i.e., non-phylogenetic) groups. These are listed below and serve as examples of groupings that are known to be artificial yet are useful for reasons of history, ecology or convenience.
- ‘inanimate life ’— living things that are not animals (i.e., in the Animal Kingdom). Using a five-kingdom classification this would include Monera (i.e., prokaryotes), Fungi, Plants and Protists. A more ecological classification is shown here, along with a list that shows where the ‘organism fact sheets fit in this classification.
- algae — aquatic photosynthetic organisms. This category spans most of the phylogenetic universe! Yet for ecological reasons, it is useful!
- macroalgae — multicellular or large colonial algae
- green algae — aquatic, photosynthetic organisms with multiple similarities to plants (pigments, cell wall chemistry, storage carbohydrates). This group is useful to know about, but for a host of reasons is difficult to define rigorously in a phylogenetic sense.
- gymnosperms — plants that have seeds but don’t have flowers. This is an historical category that is still in common use and worthwhile to be aware of. It is an example of a grouping based on the lack of a particular characteristic, something that is not generally phylogenetically sound. Other examples of artificial groups based on what they lack are:
- prokaryotes — cells without nuclei
- protists — eukaryotic organisms that are not animals, fungi, plants or prokaryotes
- bryophytes — plants (mosses, liverworts and hornworts) without vascular tissue
- fern ‘allies’— vascular plants without seeds
Further Reading and Viewing
- Go Botany Key by the Native Plant Trust. A “key” using characters to “identify” (i.e. give them a name) plants.
- A Tree of Eukaryotes by PsiWavefunction. The modern way of classifying organisms, a phylogenetic “tree” flower.
- “Phylogenetic tree view” by The Botanist in the Kitchen. Some more phylogenetic trees.
- Plants by ScienceDirect. Some more plant classification.
Media Attributions
- General Sherman Tree © Tuxyso is licensed under a CC BY-SA (Attribution ShareAlike) license

{kind=link}
{kind=link}