
Main Body
5. Types of Literacy Assessment: Principles, Procedures, and Applications
Kristen A. Munger
Abstract
This chapter focuses on key ideas for understanding literacy assessment to assist with educational decisions. Included is an overview of different literacy assessments, along with common assessment procedures used in schools and applications of assessment practices to support effective teaching. Readers of the chapter will gain an understanding of different types of assessments, how assessment techniques are used in schools, and how assessment results can inform teaching.
Learning Objectives
After reading this chapter, readers will be able to
- explain how testing fits into the larger category of assessment;
- describe different literacy assessments and how they are commonly used in schools;
- discuss why assessment findings are judged based on their validity for answering educational questions and making decisions;
- explain the importance of reliability and validity of test scores and why psychometric properties are important for interpreting certain types of assessment results;
- critique literacy assessments in terms of how they can be used or misused.
Introduction
When the topic of educational assessment is brought up, most educators immediately think of high-stakes tests used to gauge students’ progress in meeting a set of educational standards. It makes sense that much of the dialogue concerning educational assessment centers on high-stakes testing because it is this kind of assessment that is most controversial in the American education system, particularly since the vast majority of states have adopted the Common Core State Standards for English Language Arts & Literacy in History/Social Studies, Science, and Technical Subjects (CCSS; National Governors Association Center for Best Practices & Council of Chief State School Officers [NGA & CCSSO], 2010), along with high stakes tests intended to assess students’ proficiency in meeting them. But high-stakes tests are actually just a fraction of assessment procedures used in schools, and many other assessments are as important in influencing instructional decisions. This chapter discusses a wide scope of literacy assessments commonly used in kindergarten through twelfth grade classrooms, along with ways to use results to make educational decisions.
Literacy Assessment
To understand literacy assessment, we first need to think about the term “literacy,” which is discussed throughout the chapters in this textbook. Literacy has traditionally been regarded as having to do with the ability to read and write. More recently, literacy has evolved to encompass multidimensional abilities such as listening, speaking, viewing, and performing (NGA & CCSSO, 2010), along with cultural and societal factors (Snow, 2002) that can facilitate or constrain literacy development. This multidimensional definition of literacy requires educators and policy makers to conceptualize literacy in complex ways. Controversies arise when the richness of literacy is overly simplified by assessments that are not multidimensional or authentic, such as the overuse of multiple-choice questions. Educators may find the lack of authenticity of these assessments frustrating when results do not appear to represent what their students know and can do. On the other hand, more authentic assessment methods, such as observing students who are deliberating the meaning of texts during group discussions, do not precisely measure literacy skills, which can limit the kinds of decisions that can be made.
Even though the assessment of literacy using multiple choice items versus more authentic procedures seems like opposites, they do have an important feature in common: they both can provide answers to educational questions. Whether one approach is more valuable than the other, or whether both are needed, depends entirely on the kind of questions being asked. So if someone asks you if a multiple choice test is a good test or if observing a student’s reading is a better assessment procedure, your answer will depend on many different factors, such as the purpose of the assessment, along with the quality of the assessment tool, the skills of the person who is using it, and the educational decisions needing to be made. This chapter will help you learn more about how to make decisions about using literacy assessments and how to use them to improve teaching and learning.
Taxonomy of Literacy Assessments
To understand the purposes of different types of literacy assessment, it is helpful to categorize them based on their purposes. It should be noted that there is much more research on the assessment of reading compared to assessment of other literacy skills, making examples in the chapter somewhat weighted toward reading assessments. Examples of assessments not limited to reading have also been included, where appropriate, as a reminder that literacy includes reading, writing, listening, speaking, viewing, and performing, consistent with the definition of literacy provided in Chapter 1 of this textbook.
Formal Assessments
One way to categorize literacy assessments is whether they are formal or informal. Formal literacy assessments usually involve the use of some kind of standardized procedures that require administering and scoring the assessment in the same way for all students. An example of formal assessments is state tests, which evaluate proficiency in one or more literacy domains, such as reading, writing, and listening. During the administration of state tests, students are all given the same test at their given grade levels, teachers read the same directions in the same way to all students, the students are given the same amount of time to complete the test (unless the student received test accommodations due to a disability), and the tests are scored and reported using the same procedures. Standardization allows control over factors that can unintentionally influence students’ scores, such as how directions are given, how teachers respond to students’ questions, and how teachers score students’ responses. Certain state test scores are also usually classified as criterion-referenced because they measure how students achieve in reference to “a fixed set of predetermined criteria or learning standards” (edglossary.org, 2014). Each state specifies standards students should meet at each grade level, and state test scores reflect how well students achieved in relation to these standards. For example, on a scale of 1 to 4, if a student achieved a score of “2” this score would typically reflect that the student is not yet meeting the standards for their grade, and he or she may be eligible for extra help toward meeting them.
Another example of a criterion-referenced score is the score achieved on a permit test to drive a car. A predetermined cut score is used to decide who is ready to get behind the wheel of a car, and it is possible for all test takers to meet the criterion (e.g., 80% items correct or higher). Criterion-referenced test scores are contrasted with normatively referenced (i.e., norm-referenced) test scores, such as an SAT score. How a student does depends on how other students score who take the test, so there is no criterion score to meet or exceed. To score high, all a student has to do is do better than most everyone else. Norm-referenced scores are often associated with diagnostic tests, which will be described in further detail in the section of this chapter under the heading “Diagnostic Literacy Assessments.”
Informal Assessments
Informal literacy assessments are more flexible than formal assessments because they can be adjusted according to the student being assessed or a particular assessment context. Teachers make decisions regarding with whom informal assessments are used, how the assessments are done, and how to interpret findings. Informal literacy assessments can easily incorporate all areas of literacy such as speaking, listening, viewing, and performing rather than focusing more exclusively on reading and writing. For example, a teacher who observes and records behaviors of a group of students who view and discuss a video is likely engaging in informal assessment of the student’s reading, writing, speaking, listening, and/or performing behaviors.
Teachers engage in a multitude of informal assessments each time they interact with their students. Asking students to write down something they learned during an English language arts (ELA) class or something they are confused about is a form of informal assessment. Observing students engaging in cooperative learning group discussions, taking notes while they plan a project, and even observing the expressions on students’ faces during a group activity are all types of informal assessment. Likewise, observing students’ level of engagement during literacy tasks is informal assessment when procedures are flexible and individualized. Informal classroom-based self-assessments and student inventories used to determine students’ attitudes about reading may be useful toward planning and adjusting instruction as well (Afflerbach & Cho, 2011).
Methods for assessing literacy that fall somewhere between informal and formal include reading inventories, such as the Qualitative Reading Inventory-5 (QRI-5; Leslie & Caldwell, 2010). Reading inventories require students to read word lists, passages, and answer questions, and although there are specific directions for how to administer and score them, they offer flexibility in observing how students engage in literacy tasks. Reading inventories are often used to record observations of reading behaviors rather than to simply measure reading achievement.
Formative Assessments
Another useful way to categorize literacy assessments is whether they are formative or summative. Formative assessments are used to “form” a plan to improve learning. An example of formative literacy assessment might involve a classroom teacher checking how many letters and sounds her students know as she plans decoding lessons. Students knowing only a few letter sounds could be given texts that do not include letters and words they cannot decode to prevent them from guessing at words. Students who know most of their letter sounds could be given texts that contain more letters and letter combinations that they can practice sounding out (e.g., the words in their texts might include all the short vowels and some digraphs they have learned, such as sh, th, ck). In this example, using a formative letter-sound assessment helped the teacher to select what to teach rather than simply evaluate what the student knows. Formative assessment is intended to provide teachers with information to improve students’ learning, based on what students need.
Summative Assessments
Summative assessments are used to “sum up” if students have met a specified level of proficiency or learning objective. State tests fall under the category of summative assessments because they are generally given to see which students have met a critical level of proficiency, as defined by standards adopted by a particular state. Unit tests are also summative when they sum up how students did in meeting particular literacy objectives by using their knowledge related to reading, writing, listening, speaking, viewing, and performing. A spelling test can be both formative and summative. It is formative when the teacher is using the information to plan lessons such as what to reteach, and it is summative if used to determine whether students showed mastery of a spelling rule such as “dropping the ‘e’ and adding ‘-ing’.” So the goal of formative assessment is mostly to inform teaching, whereas the goal of summative assessment is to summarize the extent to which students surpass a certain level of proficiency at an end-point of instruction, such as at the end of an instructional unit or at the end of a school year.
Literacy Screenings
Another way to categorize assessments is whether they are used for screening or diagnostic purposes. Literacy screenings share characteristics with medical screenings, such as hearing and vision checks in the nurse’s office or when a patients’ blood pressure is checked at the beginning of a visit to the physician’s office. Screenings are typically quick and given to all members of a population (e.g., all students, all patients) to identify potential problems that may not be recognized during day-to-day interactions. See Table 1 for examples of commonly used universal literacy screeners, along with links to information about their use.
| Universal Literacy Screeners | Links to additional information |
| AIMSweb | http://www.aimsweb.com/ |
| Dynamic Indicators of Basic Early Literacy Skills—Next | https://dibels.uoregon.edu/ |
| STAR Reading | http://www.renaissance.com/assess |
| Phonological Awareness Literacy Screening (PALS) | https://pals.virginia.edu/ |
Among the most popular literacy screeners used in schools are the Dynamic Indicators of Basic Early Literacy Skills—Next Edition (DIBELS Next; Good & Kaminski, 2011) and AIMSweb (Pearson, 2012). These screeners include sets of items administered to all children at certain grade levels (which is why they are often called “universal” literacy screeners) to do quick checks of their literacy development and identify potential problems that may not be visible using less formal means. Literacy screenings require young children to complete one-minute tasks such as naming sounds they hear in spoken words (e.g., “cat” has the sounds /c/ /a/ /t/), naming the sounds of letters they see (e.g., letter “p” says /p/), and starting in first grade, reading words in brief passages. Universal literacy screenings such as DIBELS Next and AIMSweb are often characterized as “fluency” assessments because they measure both accuracy and efficiency in completing tasks. For these assessments, the correct number of sounds, letters, or words is recorded and compared to a research-established cut point (i.e., benchmark) to decide which students are not likely to be successful in developing literacy skills without extra help. If a student scores below the benchmark, it indicates that the task was too difficult, and detection of this difficulty can signal a need for intervention to prevent future academic problems. Intervention typically involves more intensive ways of teaching, such as extra instruction delivered to small groups of students.
To learn more about commercially available screenings such as DIBELS Next and AIMSweb, or to learn about how to create your own personalized screenings, please visit http://interventioncentral.org. This site enables teachers to create their own individualized screening probes to assess a variety of basic literacy skills, such as identifying letters and sounds, segmenting sounds in spoken words, sounding out nonsense words, reading real words in connected text, and filling in blanks in reading passages (called “maze” procedures). Teachers can select the letters, words, and passages to be included on these individualized assessments. Probes to assess students’ math and writing skills can also be created; however, any customized screening probes should be used with caution, since they do not share the same measurement properties as well-researched screenings such as DIBELS Next and AIMSweb.
Diagnostic Literacy Assessments
The purposes of universal literacy screenings can be contrasted with those of diagnostic literacy assessments. Unlike literacy screeners, diagnostic tests are generally not administered to all students but are reserved for students whose learning needs continue to be unmet, despite their receiving intensive intervention. Diagnostic literacy assessments typically involve the use of standardized tests administered individually to students by highly trained educational specialists, such as reading teachers, special educators, speech and language pathologists, and school psychologists. Diagnostic literacy assessments include subtests focusing on specific components of literacy, such as word recognition, decoding, reading comprehension, and both spoken and written language. Results from diagnostic assessments may be used formatively to help plan more targeted interventions for students who do not appear to be responding adequately, or results can be combined with those from other assessments to determine whether students may have an educational disability requiring special education services.
An example of a widely used diagnostic literacy test is the Wechsler Individual Achievement Test-Third Edition (WIAT-III; Wechsler, 2009). The WIAT-III is typically used to assess the achievement of students experiencing academic difficulties who have not responded to research-based interventions. The WIAT-III includes reading, math, and language items administered according to the age of the student and his or her current skill level. The number of items the student gets correct (the raw score) is converted to a standard score, which is then interpreted according to where the student’s score falls on a bell curve (see Figure 1) among other students the same age and grade level who took the same test (e.g., the normative or “norm” sample).
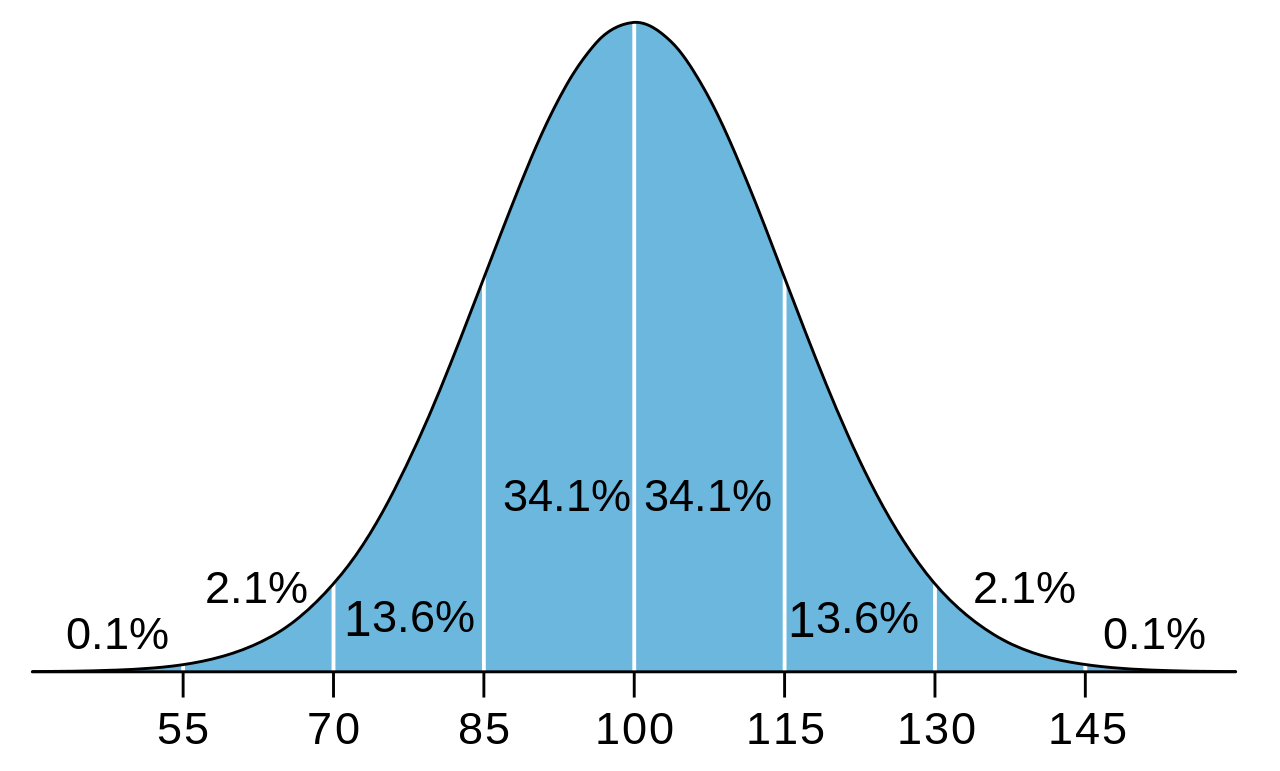
Most students will score in the middle of the distribution, but some students will achieve extreme scores—either higher or lower than most other students. This is why the “tails” at either side of the bell curve slope downward from the big hump in the middle—this illustrates the decreasing frequency of scores that are especially low or high. In other words, the more extreme the score, the fewer students are likely to achieve it. When students achieve at either extreme, it can signal the need for more specialized instruction related to the individual needs of the student (e.g., intervention or gifted services).
Diagnostic achievement tests are frequently referred to as “norm-referenced” (edglossary.org, 2013) because their scores are compared to scores of students from a norm sample. A norm sample is a group of individuals who were administered the same test items in the same way (i.e., using standardized procedures) while the test was being developed. Students who take the test have their performance compared to that of students from the norm sample to make meaning of the score. For example, if a student were given a diagnostic assessment and the score fell within the same range as most of the students in the norm sample, then his or her score would be considered “average.” If the student’s score fell much higher or lower than other students in the norm sample, then the score would not be considered average or typical because most of the other students did not score at either of these extremes.
Comparing students’ scores to a norm sample helps identify strengths and needs. Then again, just knowing where students’ scores fall on a bell curve does nothing to explain why they scored that way. An extremely low score may indicate a learning problem, or, it may signal a lack of motivation on the part of the student while taking the test. Perhaps a low score could even be due to a scoring error made by the tester. Even though a score from a diagnostic assessment may be quite precise, understanding why a student scored at a particular level requires additional information. Did observations during testing show that the student was distracted, uncooperative, or was squinting at items? It is often a combination of assessment information that helps identify why a student may have scored a certain way and is why testers often use their observations during testing to interpret the meaning of scores.
Group achievement tests such as The Iowa Test of Basic Skills (ITBS; Hoover Dunbar, & Frisbie, 2003) that include literacy subtests have properties that make them function somewhat like a screening and somewhat like a diagnostic test. Like screeners, they are administered to all students at a particular grade level, but unlike most screeners, they take more time to complete and are administered to entire classrooms rather than having at least some sections administered individually. Like diagnostic tests, they tend to produce scores that are norm-referenced. Students’ performance is compared to a norm group to see how they compare among peers, but unlike diagnostic tests, the tester is not able to discern how well scores represent students’ abilities because testers are not able to observe all of the students’ testing behaviors that may impact the interpretation of scores (e.g., levels of engagement, motivation).
For many diagnostic literacy tests, reviews are available through sources such as the Mental Measurements Yearbook (MMY). Versions of the MMY are available in hard copy at many libraries, as well as online for free for students at colleges and universities whose libraries pay a fee for access. Reviews are typically completed by experts in various fields, including literacy and measurement experts. Reviews also include complete descriptions of the test or assessment procedure, who publishes it, how long it takes to administer and score, a review of psychometric properties, and a critique of the test in reference to decisions people plan to make based on findings. It is important for teachers and other educators who use tests to understand the benefits and problems associated with selecting one test over another, and resources such as the MMY offer reviews that are quick to locate, relatively easy to comprehend (when one has some background knowledge in assessment), and are written by people who do not profit from the publication and sale of the assessment.
Single Point Estimates
Literacy assessments that are completed only one time provide a single point estimate of a student’s abilities. An example of a single point estimate is a student’s word identification score from a diagnostic achievement test. If the student’s score is far below what is expected for his or her age or grade level, then the score signals a need to determine what is at the root of low performance. Alternatively, a single low score does not necessarily signal a lack of ability to learn, since with a change in instruction, the student might begin to progress much faster and eventually catch up to his or her typical age-based peers. To assess a student’s rate of learning, progress-monitoring assessments are needed.
Progress-Monitoring Literacy Assessments
To monitor a student’s progress in literacy, assessments are needed that actually measure growth. Rather than just taking a snapshot of the student’s achievement at a single point in time, progress-monitoring assessments provide a baseline (i.e., the starting point) of a student’s achievement, along with periodic reassessment as he or she is progressing toward learning outcomes. Such outcomes might include achieving a benchmark score of correctly reading 52 words per minute on oral reading fluency passages or a goal of learning to “ask and answer key details in a text” (CCSS.ELA-Literacy.RL.1.2) when prompted, with 85% accuracy. The first outcome of correctly reading 52 words per minute would likely be measured using progress-monitoring assessments, such as DIBELS Next and AIMSweb. These screeners are not only designed to measure the extent to which students are at risk for future literacy-related problems at the beginning of the school year but also to monitor changes in progress over time, sometimes as often as every one or two weeks, depending on individual student factors. The second outcome of being able to “ask and answer key details in a text” could be monitored over time using assessments such as state tests or responses on a qualitative reading inventory. Being able to work with key details in a text could also be informally assessed by observing students engaged in classroom activities where this task is practiced.
Unlike assessments that are completed only one time, progress-monitoring assessments such as DIBELS Next and AIMSweb feature multiple, equivalent versions of the same tasks, such as having 20 oral reading fluency passages that can be used for reassessments. Using different but equivalent passages prevents artificial increases in scores that would result from students rereading the same passage. Progress-monitoring assessments can be contrasted with diagnostic assessments, which are not designed to be administered frequently. Administering the same subtests repeatedly would not be an effective way to monitor progress. Some diagnostic tests have two equivalent versions of subtests to monitor progress infrequently—perhaps on a yearly basis—but they are simply not designed for frequent reassessments. This limitation of diagnostic assessments is one reason why screeners like DIBELS Next and AIMSweb are so useful for determining how students respond to intervention and why diagnostic tests are often reserved for making other educational decisions, such as whether a student may have an educational disability.
Progress-monitoring assessments have transformed how schools determine how a student is responding to intervention. For example, consider the hypothetical example of Jaime’s progress-monitoring assessment results in second grade, shown in Figure 2. Jaime was given oral reading fluency passages from a universal literacy screener, and then his progress was monitored to determine his response to a small group literacy intervention started in mid-October. Data points show the number of words Jaime read correctly on each of the one-minute reading passages. Notice how at the beginning of the school year, his baseline scores were extremely low, and when compared to the beginning of the year second grade benchmark (Dynamic Measurement Group, 2010) of 521 words per minute (Good & Kaminski, 2011), they signaled he was “at risk” of not reaching later benchmarks without receiving intensive intervention. Based on Jaime’s baseline scores, intervention team members decided that he should receive a research-based literacy intervention to help him read words more easily so that his oral reading fluency would increase at least one word per week. This learning goal is represented by the “target slope” seen in Figure 2. During the intervention phase, progress-monitoring data points show that Jaime began making improvements toward this goal, and the line labeled “slope during intervention” shows that he was gaining at a rate slightly faster than his one word per week goal.

When looking at Jaime’s baseline data, notice how the data points form a plateau. If his progress continued at this same rate, by the end of the school year, he would be even farther behind his peers and be at even greater risk for future reading problems. When interpreting the graph in Figure 2, it becomes clear that intensive reading intervention was needed. Notice after the intervention began how Jaime’s growth began to climb steeply. Although he appeared to be responding positively to intervention, in reality, by the end of second grade, students whose reading ability progresses adequately should be reading approximately 90 words correctly per minute (Good & Kaminski, 2011). Based on this information, Jaime is not likely to reach the level of reading 90 words correctly by the end of second grade and will probably only reach the benchmark expected for a student at the beginning of second grade. These assessment data suggest that Jaime’s intervention should be intensified for the remainder of second grade to accelerate his progress further. It is also likely that Jaime will need to continue receiving intervention into third grade, and progress monitoring can determine, along with other assessment information, when his oral reading fluency improves to the point where intervention may be changed, reduced, or even discontinued. You may wonder how the intervention team would determine whether Jaime is progressing at an adequate pace when he is in third grade. Team members would continue to monitor Jaime’s progress and check to make sure his growth line shows that he will meet benchmark at the end of third grade (i.e., correctly reading approximately 100 words per minute; Good & Kaminski, 2011). If his slope shows a lack of adequate progress, his teachers can revisit the need for intervention to ensure that Jaime does not fall behind again.
Some schools monitor their students’ progress using computer-adapted assessments, which involve students responding to test items delivered on a computer. Computer-adapted assessments are designed to deliver specific test items to students, and then adapt the number and difficulty of items administered according to how students respond (Mitchell, Truckenmiller, & Petscher, 2015). Computer-adapted assessments are increasing in popularity in schools, in part, because they do not require a lot of time or effort to administer and score, but they do require schools to have an adequate technology infrastructure. The reasoning behind using these assessments is similar to other literacy screeners and progress-monitoring assessments—to provide effective instruction and intervention to meet all students’ needs (Mitchell et al., 2014).
Although many literacy screening and progress-monitoring assessment scores have been shown to be well-correlated with a variety of measures of reading comprehension (see, for example, Goffreda & DiPerna, 2010) and serve as reasonably good indicators of which students are at risk for reading difficulties, a persistent problem with these assessments is that they provide little guidance to teachers about what kind of literacy instruction and/or intervention a student actually needs. A student who scores low at baseline and makes inadequate progress on oral reading fluency tasks may need an intervention designed to increase reading fluency, but there is also a chance that the student lacks the ability to decode words and really needs a decoding intervention (Murray, Munger, & Clonan, 2012). Or it could be that the student does not know the meaning of many vocabulary words and needs to build background knowledge to read fluently (Adams, 2010-2011), which would require the use of different assessment procedures specifically designed to assess and monitor progress related to these skills. Even more vexing is when low oral reading fluency scores are caused by multiple, intermingling factors that need to be identified before intervention begins. When the problem is more complex, more specialized assessments are needed to disentangle the factors contributing to it.
A final note related to progress-monitoring procedures is the emergence of studies suggesting that there may be better ways to measure students’ progress on instruments such as DIBELS Next compared to using slope (Good, Powell-Smith, & Dewey, 2015), which was depicted in the example using Jaime’s data. In a recent conference presentation, Good (2015) argued that the slope of a student’s progress may be too inconsistent to monitor and adjust instruction, and he suggested a new (and somewhat mathematically complex) alternative using an index called a student growth percentile. A student growth percentile compares the rate at which a student’s achievement is improving in reference to how other students with the same baseline score are improving. For example, a student reading 10 correct words per minute on an oral reading fluency measure whose growth is at the 5th percentile is improving much more slowly compared to the other children who also started out reading only 10 words correctly per minute. In this case, a growth percentile of five means that the student is progressing only as well as or better than five percent of peers who started at the same score, and also means that the current instruction is not meeting the student’s needs. Preliminary research shows some promise in using growth percentiles to measure progress as an alternative to slope, and teachers should be on the lookout for more research related to improving ways to monitor student progress.
Linking Assessment to Intervention
How can teachers figure out the details of what a student needs in terms of intervention? They would likely use a variety of informal and formal assessment techniques to determine the student’s strengths and needs. The situation might require the use of diagnostic assessments, a reading or writing inventory, the use of observations to determine whether the student is engaged during instruction, and/or the use of assessments to better understand the student’s problem-solving and other thinking skills. It may be a combination of assessment techniques that are needed to match research-based interventions to the student’s needs.
You may be starting to recognize some overlap among different types of assessments across categories. For example, state tests are usually both formal and summative. Literacy screeners and progress-monitoring assessments are often formal and formative. And some assessments, such as portfolio assessments, have many overlapping qualities across the various assessment categories (e.g., portfolios can be used formatively to guide teaching and used summatively to determine if students met an academic outcome).
In bringing up portfolio assessments, this takes us back to points raised at the beginning of this chapter related to the authenticity of literacy assessments. So why do multiple choice tests exist if options such as portfolio assessment, which are so much more authentic, are an option? High-quality multiple choice tests tend to have stronger psychometric properties (discussed in the next section) than performance assessments like portfolios, which make multiple choice tests desirable when assessment time is limited and scores need to have strong measurement properties. Multiple choice test items are often easy to score and do not require a great deal of inference to interpret (i.e., they are “objective”), which are some of the reasons why they are popularly used. Portfolio assessments often take longer to do but also reflect the use of many important literacy skills that multiple choice items simply cannot assess. Based on this discussion, you may wonder if portfolio assessments are superior to multiple choice tests, or if the reverse is true. As always, an answer about a preferred format depends on the purpose of the assessment and what kinds of decisions will be made based on findings.
Psychometric Principles of Literacy Assessment
A chapter about literacy assessment would not be complete without some discussion about psychometric properties of assessment scores, such as reliability and validity (Trochim, 2006). Reliable assessment means that the information gathered is consistent and dependable—that the same or similar results would be obtained if the student were assessed on a different day, by a different person, or using a similar version of the same assessment (Trochim, 2006). To think about reliability in practice, imagine you were observing a student’s reading behaviors and determined that the student was struggling with paying attention to punctuation marks used in a storybook. You rate the student’s proficiency as being a one on a one to four scale, meaning he or she reads as though no punctuation marks were noticed. Your colleague observed the student reading the same book at the same time you were observing, and he rated the student’s proficiency as a “three,” meaning that the student was paying attention to most of the punctuation in the story, but not all. The difference between your rating and your colleague’s rating signals a lack of reliability among raters using that scale. If these same inconsistencies in ratings arose across other items on the reading behavior scale or with other students, you would conclude that the scale has problems. These problems could include that the scale is poorly constructed, or that there may simply be inter-rater reliability problems related to a lack of training or experience with the people doing the ratings.
Reliability of formal assessment instruments, such as tests, inventories, or surveys, is usually investigated through research that is published in academic journal articles or test manuals. This kind of research involves administering the instrument to a sample of individuals, and findings are reported based on how those individuals scored. These findings provide “estimates” of the test’s reliability, since indexes of reliability will vary to a certain degree, depending on the sample used in the research. The more stable reliability estimates are across multiple diverse samples, the more teachers can count on scores or ratings being reliable for their students. When reliability is unknown, then decisions made based on assessment information may not be trustworthy. The need for strong reliability versus the need for authenticity (i.e., how well the assessment matches real life literacy situations) is a rivalry that underlies many testing debates.
In addition to assessments needing to be reliable, information gathered from assessments must also be valid for making decisions. A test has evidence of validity when research shows that it measures what it is supposed to measure (Trochim, 2006). For example, when a test that is supposed to identify students at risk for writing problems identifies students with actual writing problems, then this is evidence of the test’s validity. A weekly spelling test score may lack evidence of validity for applied spelling ability because some students may just be good memorizers and not be able to spell the same words accurately or use the words in their writing. When assessment information is not reliable, then it cannot be valid, so reliability is a keystone for the evaluation of assessments.
Sometimes, a test that seems to test what it is supposed to test will have issues with validity that are not apparent. For example, if students are tested on math applications problems to see who may need math intervention, a problem could arise if the children may not be able to read the words in the problems. In this case, the students may get many items incorrect, making the math test more like a reading test for these students. It is research on validity and observations by astute educators that help uncover these sorts of problems and prevent the delivery of a math intervention when what may actually be needed is a reading intervention.
The validity issue described above is one reason why some students may receive accommodations (e.g., reading a test to students) because accommodations can actually increase the validity of a test score for certain students. If students with reading disabilities had the above math test read to them, then their resulting scores would likely be a truer indicator of math ability because the accommodation ruled out their reading difficulties. This same logic applies to English language learners (ELLs) who can understand spoken English much better than they can read it. If a high school exam assessing knowledge of biology is administered and ELL students are unable to pass it, is it because they do not know biology or is it because they do not know how to read English? If the goal is to assess their knowledge of biology, then the test scores may not be valid.
Another example of a validity issue occurs if a student with visual impairment were assessed using a reading task featuring print in 12-point font. If the student scored poorly, would you refer him or her for reading intervention? Hopefully, not. The student might actually need reading intervention, but there is a validity problem with the assessment results, so that in reality, you would need more information before making any decisions. Consider that when you reassess the student’s reading using large print that the student’s score increases dramatically. You then know that it was a print size problem and not a reading problem that impacted the student’s initial score. On the other hand, if the student still scored low even with appropriately enlarged print, you would conclude that the student may have a visual impairment and a reading problem, in which case providing reading intervention, along with the accommodation of large print material, would be needed.
Some Controversies in Literacy Assessment
While there is little controversy surrounding literacy assessments that are informal and part of normal classroom practices, formal assessments activate huge controversy in schools, in research communities, on Internet discussion boards, and in textbooks like this. When considering the scope of educational assessment, one thing is clear: many school districts give far too many tests to far too many students and waste far too many hours of instruction gathering data that may or may not prove to have any value (Nelson, 2013). The over testing problem is especially problematic when so much time and effort go into gathering data that do not even end up being used. Whether a school is overwhelmed with testing is not universal. School districts have a great deal of influence over the use of assessments, but all too often when new assessments are adopted, they are added to a collection of previously adopted assessments, and the district becomes unsure about which assessments are still needed and which should be eliminated. Assessments also are added based on policy changes at federal and state levels. For example, the passing of the No Child Left Behind Act of 2001 (NCLB, 2002) expanded state testing to occur in all grades three through eight, compared to previous mandates which were much less stringent.
Some tests are mandated for schools to receive funding, such as state tests; however, the use of other assessments is largely up to school districts. It is important for educators and school leaders to periodically inventory procedures being used, discuss the extent to which they are needed, and make decisions that will provide answers without over testing students. In other words, the validity of assessments is not only limited to how they are used with individual students but must be evaluated at a larger system level in which benefits to the whole student body are also considered. When assessments provide data that are helpful in making instructional decisions but also take away weeks of instructional time, educators and school leaders must work toward solutions that maximize the value of assessments while minimizing potential negative effects. Not liking test findings is a different issue than test findings not being valid. For example if a test designed to identify students behind in reading is used to change instruction, then it may be quite valuable, even if it is unpleasant to find out that many students are having difficulty.
As a society, we tend to want indicators of student accountability, such as that a minimum standard has been met for students to earn a high school diploma. Often, earning a diploma requires students to pass high-stakes exit exams; however, this seemingly straightforward use of test scores can easily lead to social injustice, particularly for students from culturally and linguistically diverse backgrounds. Because high-stakes tests may be inadequate at providing complete information about what many students know and can do, the International Reading Association (IRA, 2014) released a position statement that included the following recommendation:
High school graduation decisions must be based on a more complete picture of a student’s literacy performance, obtained from a variety of systematic assessments, including informal observations, formative assessments of schoolwork, and consideration of out-of-school literacies, as well as results on standardized formal measures. (p. 2)
The IRA recommends that “teacher professional judgment, results from formative assessments, and student and family input, as well as results from standardized literacy assessments” (p. 5) serve as adequate additions in making graduation decisions. There is no easy answer for how to use assessments to precisely communicate how well students are prepared for college, careers, and life, and we are likely many reform movements away from designing a suitable plan. Nevertheless, the more educators, families, and policy-makers know about assessments—including the inherent benefits and problems that accompany their use—the more progress can be made in refining techniques to make informed decisions designed to enhance students’ futures. Literacy assessments can only be used to improve outcomes for students if educators have deep knowledge of research-based instruction, assessment, and intervention and can use that knowledge in their classrooms. For this reason, information from this chapter should be combined with other chapters from this book and other texts outlining the use of effective literacy strategies, including students who are at risk for developing reading problems or who are English language learners.
Summary
Although literacy assessment is often associated with high-stakes standardized tests, in reality, literacy assessments encompass an array of procedures to help teachers make instructional decisions. This chapter highlighted how teachers can use literacy assessments to improve instruction, but in reality, assessment results are frequently used to communicate about literacy with a variety of individuals, including teams of educators, specialists, and family and/or community members. Knowing about the different kinds of assessments and their purposes will allow you to be a valuable addition to these important conversations.
Literacy assessments can be informal or formal, formative or summative, screenings or diagnostic tests. They can provide data at single points in time or to monitor progress over time. Regardless of their intended purpose, it is important that assessment information be trustworthy. It is also important that teachers who use assessments understand associated benefits and difficulties of different procedures. An assessment that is ideal for use in one circumstance may be inappropriate in another. For this reason, teachers who have background in assessment will be better equipped to select appropriate assessments which have the potential to benefit their students, and they also will be able to critique the use of assessments in ways that can improve assessment practices that are more system-wide. Literacy assessments are an important part of educational decision making, and therefore, it is essential that teachers gain a thorough understanding of their uses and misuses, gain experience interpreting information obtained through assessment, and actively participate in reform movements designed not just to eliminate testing but to use assessments in thoughtful and meaningful ways.
Questions and Activities
- Using some of the terms learned from this chapter, discuss some commonly used high-stakes literacy assessments, such as state-mandated tests or other tests used in schools.
- Explain ways in which some forms of literacy assessment are more controversial than others and how the more controversial assessments are impacting teachers, students, and the education system.
- What are the differences between formative and summative assessments? List some examples of each and how you currently use, or plan to use these assessments in your teaching.
- A colleague of yours decides that she would like to use a diagnostic literacy test to assess all students in her middle school to see who has reading, spelling, and/or writing problems. The test must be administered individually and will take approximately 45 minutes per student. Although there is only one form of the assessment, your colleague would like to administer the test three times per year. After listening carefully to your colleague’s ideas, what other ideas do you have that might help meet your colleague’s goal besides the use of a diagnostic literacy test?
References
Adams, M. J. (2010-2011, Winter). Advancing our students’ language and literacy: The challenge of complex texts. American Educator, 34, 3-11, 53. Retrieved from http://www.aft.org/sites/default/files/periodicals/Adams.pdf
Afflerbach, P., & Cho, B. Y. (2011). The classroom assessment of reading. In M. J. Kamil, P. D. Pearson, E. B. Moje, & P. P. Afflerbach (Eds.), Handbook of reading research (Vol. 4, pp. 487-514). New York, NY: Routledge.
Dynamic Measurement Group (2010, December 1). DIBELS Next benchmark goals and composite scores. Retrieved from https://dibels.uoregon.edu/docs/DIBELSNextFormerBenchmarkGoals.pdf
Edglossary (2013, August 29). Norm-referenced test [online]. Retrieved from http://edglossary.org/norm-referenced-test/
Edglossary (2014, April 30). Criterion-referenced test [online]. Retrieved from http://edglossary.org/criterion-referenced-test/
Goffreda, C. T., & DiPerna, J. C. (2010). An empirical review of psychometric evidence for the Dynamic Indicators of Basic Early Literacy Skills. School Psychology Review, 39, 463-483. Available at http://www.nasponline.org/publications/periodicals/spr/volume-39/volume-39-issue-3/an-empirical-review-of-psychometric-evidence-for-the-dynamic-indicators-of-basic-early-literacy-skills
Good, R. H. (2015, May 19). Improving the efficiency and effectiveness of instruction with progress monitoring and formative evaluation in the outcomes driven model. Invited presentation at the International Conference on Cognitive and Neurocognitive Aspects of Learning: Abilities and Disabilities, Haifa, Israel. Retrieved from https://dibels.org/papers/Roland_Good_Haifa_Israel_2015_Handout.pdf
Good, R. H., & Kaminski, R. A. (Eds.). (2011). DIBELS Next assessment manual. Eugene, OG: Dynamic Measurement Group, Inc. Retrieved from http://www.d11.org/edss/assessment/DIBELS%20NextAmplify%20Resources/DIBELSNext_AssessmentManual.pdf
Good, R. H., Powell-Smith, K. A., & Dewey, E. (2015, February). Making reliable and stable progress decisions: Slope or pathways of progress? Poster presented at the Annual Pacific Coast Research Conference, Coronado, CA.
Hoover, H. D., Dunbar, S. B., & Frisbie, D. A. (2003). The Iowa Tests: Guide to research and development. Chicago, IL: Riverside Publishing.
International Reading Association. (2014). Using high-stakes assessments for grade retention and graduation decisions: A position statement of the International Reading Association. Retrieved from http://www.literacyworldwide.org/docs/default-source/where-we-stand/high-stakes-assessments-position-statement.pdf
Leslie, L., & Caldwell, J. S. (2010). Qualitative reading inventory-5. Boston, MA: Pearson.
Mitchell, A. M., Truckenmiller, A., & Petscher, Y. (2015, June). Computer-adapted assessments: Fundamentals and considerations. Communique, 43(8), 1, 22-24.
Murray, M. S., Munger, K. A., & Clonan, S. M. (2012). Assessment as a strategy to increase oral reading fluency. Intervention in Schools and Clinic, 47, 144-151. doi:10.1177/1053451211423812
National Governors Association Center for Best Practices & Council of Chief State School Officers. (2010). Common Core State Standards for English Language Arts & Literacy in History/Social Studies, Science, and Technical Subjects. Washington, DC: Author. Retrieved from http://www.corestandards.org/assets/CCSSI_ELA%20Standards.pdf
Nelson, H. (2013). Testing more, teaching less: What American’s obsession with student testing costs in money and lost instructional time. Retrieved from http://www.aft.org/sites/default/files/news/testingmore2013.pdf
No Child Left Behind Act of 2001, Pub. L. No. 107-110, 115 Stat. 1425 (2002).
Pearson. (2012). AIMS web technical manual (R-CBM and TEL). NCS Pearson, Inc. Retrieved from http://www.aimsweb.com/wp-content/uploads/aimsweb-Technical-Manual.pdf
Snow, C. (Chair). (2002). RAND reading study group: Reading for understanding, toward an R&D program in reading comprehension. Santa Monica, CA: RAND. Retrieved from http://www.rand.org/content/dam/rand/pubs/monograph_reports/2005/MR1465.pdf
Trochim, W. K. (2006). Research methods knowledge base: Construct validity. Retrieved from http://www.socialresearchmethods.net/kb/relandval.php
Wechsler, D. (2009). Wechsler Individual Achievement Test (3rd ed.). San Antonio, TX: Pearson.
Photo Credit
- Image in Figure 1 by Wikimedia, CCBY-SA 3.0 https://upload.wikimedia.org/wikipedia/commons/3/39/IQ_distribution.svg
Endnotes
1: The benchmark of 52 words per minute is considered a “criterion-referenced” score because a student’s performance is judged against a criterion—in this case, the benchmark. Recall that scores obtained on diagnostic literacy assessments are norm-referenced because they are judged against how others in a norm group scored. Some progress-monitoring assessments provide both criterion-referenced and norm-referenced scores to aid in decision-making when more than one type of score is needed. Return
